☝️ JVM (Java Virtual Machine)
- Java 바이트 코드를 실행하는 가상머신
- Java 코드가 OS 위에서 바로 실행되는 게 아니라 JVM 위에서 실행되기 때문에 OS에 종속되지 않고 실행 가능
→ Write Once, Run Anywhere
[Java Execution Flow]
.java
↓ (javac 컴파일)
.class (바이트코드)
↓
JVM *
↓
CPU 실행
🧱 JVM의 구조
- JVM은 크게 세 부분으로 나뉨
1. Class Loader
2. Runtime Data Areas (메모리 영역)
3. Execution Engine
[JVM Architecture]

[JVM Execution Flow]
1. javac → 바이트코드 생성
2. JVM 실행
3. Class Loader가 클래스 로드
4. Runtime Memory 영역에 배치
5. Execution Engine이 실행
6. 필요하면 GC 수행
1) Class Loader
- 클래스(.class)를 메모리에 올리는 역할
[동작 단계]
1. Loading
• .class 파일을 읽어옴
2. Linking
• Verification (바이트코드 검증)
• Preparation (static 변수 메모리 할당)
• Resolution (심볼릭 -> 실제 참조 연결)
3. Initialization
• Static 블록 실행
• Static 변수 값 초기화
2) Runtim Data Area
- JVM 메모리 영역
- 자바 프로그램이 실행되는 동안 JVM이 메모리를 용도별로 나눠 관리하는 영역
- 모든 스레드가 공유하는 영역 (
Heap,Method Area) / 스레드별 영역 (Stack,PC Register,Native Method Stack)
[Runtime Data Area Architecture]
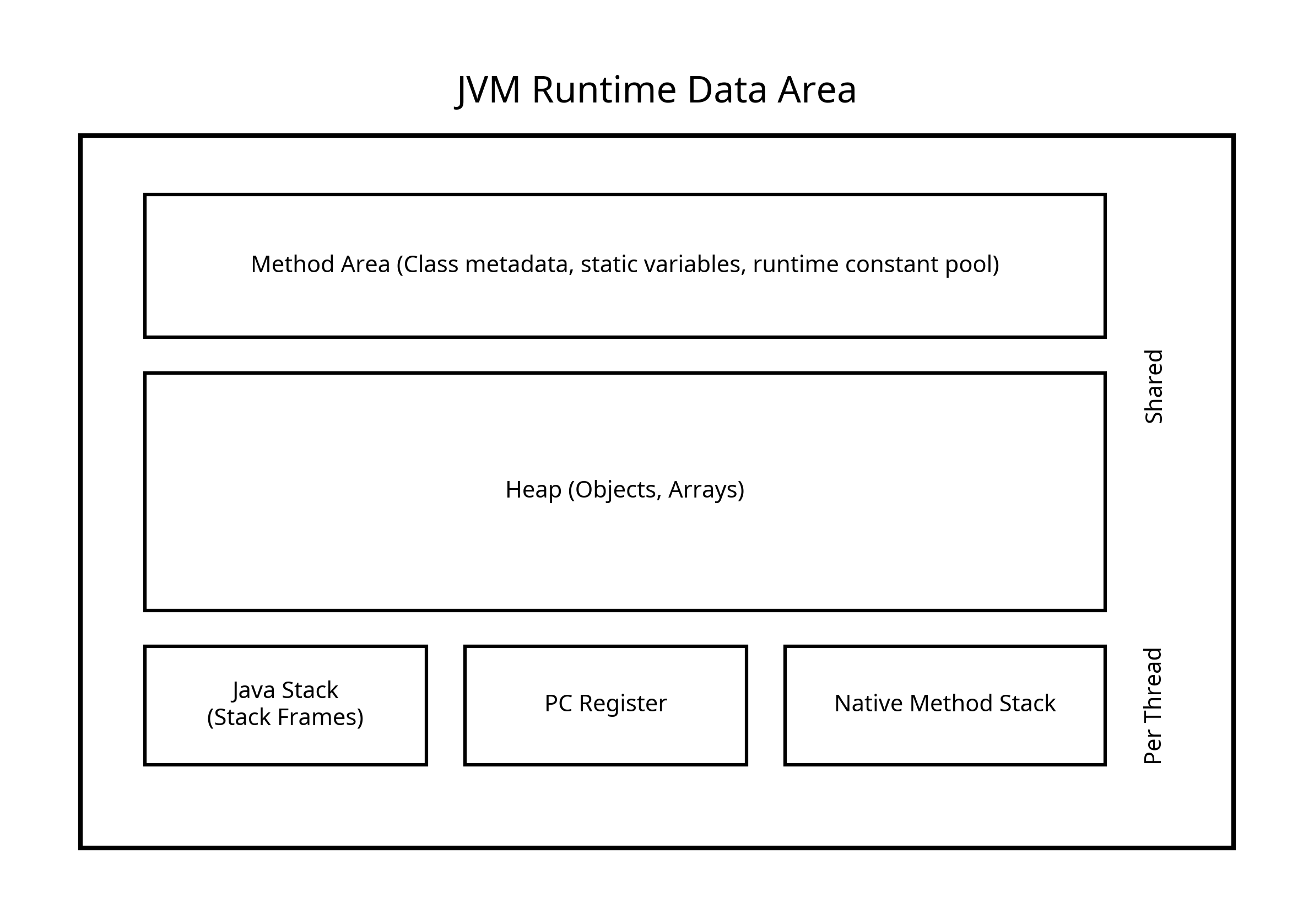
🔹 구성
2-1. Method Area (Metaspace)
- 클래스 단위 공유 영역 (모든 스레드 공유)
- 클래스 정보, 메타데이터 (클래스 이름, 상속 정보, 접근 플래그 등)
- static 변수 (큰 틀에서는 클래스 단위로 관리)
- 상수풀 (Runtime Constant Pool)
- 필드/메소드 정보 (시그니처, 바이트코드, 어노테이션 등)
- 관련 이슈 :
OutOfMemoryError : Metaspace
→ 클래스 로딩이 많거나(동적 생성/프록시 남발) 언로드가 안 되면 메모리 압박
💡 Runtime Constant Pool (상수/심볼 참조 테이블)
- 클래스 파일의 constant pool에서 로드된 정보 저장
ex. 리터럴(숫자, 문자열 등), 클래스/메소드/필드에 대한 심볼릭 레퍼런스(이름 기반 참조)
- 링킹/해결 과정에서 심볼 참조가 실제 메모리 참조로 바뀌며 실행
→ 상수 풀을 통해 실제 메소드, 필드로 연결
2-2. Heap
- 객체 저장 영역 (모든 스레드 공유)
- new 생성자로 생성한 객체, 배열 등이 이 공간에 생성됨 (객체의 !실체! 저장)
- 모든 스레드가 공유
- GC 대상
- 관련 이슈 :
OutOfMemoryError : Java heap space
→ 객체가 많이 생성/해제되는 패턴에서 GC 부하
2-3. Stack
- 스레드별 공유 영역
- 스레드마다 한 개씩 있고, 메소드 호출과 리턴이 쌓이는 구조 (메소드 호출 기록)
- 메소드가 호출될 때마다
Stack Frame한 개가 push됨 - 관련 이슈 :
StackOverflowError
→ 재귀 호출시 호출 횟수가 지나치게 많이 쌓이거나 프레임이 큰 메소드 호출 반복 등
💡Stack Frame의 구성
1. Local Variables (로컬 변수 배열)
- 매개변수, 지역변수
- 기본타입 값 (int, long 등) 또는 객체 참조 (reference)
→ 객체의 실체는 Heap에 생성되어 있고, 스택에는 객체의 참조값을 저장
2. Operand Stack (피연산자 스택)
- 바이트코드가 계산할 때 사용하는 임시 스택
ex.iadd,invokevirtual같은 명령이 여기서 pop/push 하며 동작
3. Frame Data
- 상수풀 참조, 메소드 리턴 정보 등
2-4. PC Register
- 스레드별 공유 영역
- 스레드마다 현재 실행 중인 바이트코드의 위치(주소/인덱스)를 저장
- 각 스레드는 자기 실행 위치를 따로 기억해야 함
2-5. Native Method Stack
- 스레드별 공유 영역
- Java가 아닌 C/C++ 등 네이티브 메서드를 호출할 때 사용하는 스택
- JVM 스택과 분리되어 있는 구현이 많음
3) Execution Engine
- JVM이
.class(바이트코드)를 실제로 실행해서 CPU가 돌릴 수 있는 형태로 만들고, 실행 중 필요한 최적화를 수행하는 영역 - 클래스 로딩/검증이 완료된 실행 가능한 바이트코드를 해석(Interpreter)하거나 머신 코드로 컴파일(JIT)
- 실행 중 프로파일링/최적화/디옵티마이즈와 같은 성능 작업까지 수행
🔹 구성
3-1. Interpreter
- 바이트코드를 한 줄씩 읽고 즉시 실행
- 컴파일 준비시간이 없기 때문에 시작이 빠름
- 반복 실행되는 코드의 수행 시간이 느림 (매번 다시 해석해야 함)
3-2. JIT(Just In Time) Compiler
- 자주 쓰이는 코드를 기계어로 컴파일 (Hot Spot)
- 메소드 호출 횟수, 루프 반복 횟수 등 실행 프로파일을 보고 판단 (데이터 기반, 동적 컴파일)
- CPU에서 기계어를 바로 실행
- Java 프로그램 실행 속도 점점 빨라짐
3-3. Garbage Collector
- Heap 영역의 메모리 관리
[GC Flow]
1. 사용되지 않는 객체 탐색 (Mark)
2. 메모리 회수 (Sweep)
3. 힙 공간 정리 (compaction)
[EX. GC 대상 - 참조가 끊긴 객체]
CreateObj obj = new CreateObj();
obj = null;
'Develop > Spring' 카테고리의 다른 글
| [JUnit] @SpringBootTest에서 Profile 설정하기 (0) | 2025.02.06 |
|---|---|
| [React + Spring Boot] 블로그 구현 (0) | 2021.09.24 |
