1. 가상머신 설치

vmware, ubuntu 다운로드
*vmware: 윈도우에서 다른 OS를 추가적으로 사용할 수 있게 하는 툴

설치 시작

동의한다.

Typical 선택
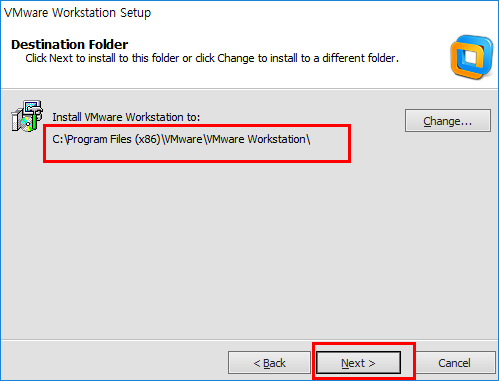
C드라이브 아래 경로 지정

업데이트 관련해서는 체크를 해제했다.

next

용량의 여유가 있기 때문에 2기가바이트로 늘렸다.
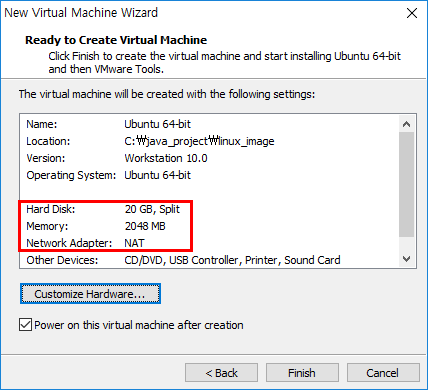
마침
typical 선택... 넘버 넣고... 우분투 설정하고... 리눅스 폴더를 만들어 설정하고... 용량을 2기가로 올렸다...
아이디 javauser 비밀번호 123456
뭐가 안되서... 캡쳐가 다 날아갔다..!
재부팅을 하면 된다ㅠㅠ
2. 우분트 리눅스 설치

어쩌저찌 설치중..... 내 캡쳐......

설치가 완료되었다.
설치 과정에서 설정했던 비밀번호를 입력해 로그인 한다.

오오..
3. JDK 설치
명령창 열기: Alt + Ctrl + t

java -version: 설치가 되어 있는지 확인
없다면, 설치 관리자를 업데이트 한다.
1)슈퍼 유저 되기:
su - (완전 전환) / sudu 명령만 슈퍼유저(일시적)
sudo apt-get update
sudo apt-get upgrade
*스펠링을 틀리지 않아야 한다. 숫자는 위의 자판으로 치도록 한다.
2)새로운 repository 등록
sudo add-apt-repository ppa:webpud8team/java
-> does not exist가 뜬다면,
java.sun.com
확장자 rpm = red package management(red hat package)
내가 필요한 건 tar.gz



그런데, 다운로드를 받으려고 하니 로그인을 하라고 한다.
openjdk.java.net

그냥 오픈된 jdk를 받도록 한다.
*리눅스에서 다운받아야 한다!



위치를 Downloads로 옮긴다.

현재위치 확인하고

ls는 list의 약자. 윈도우에서 쓰는 dir이다. 다운로드가 잘 되었다.

압축을 해제한다.
*압축해제 명령: sudo tar zxvf xxxx.tar.gz

압축이 해제되어 jdk-14.0.1이라는 폴더가 생성되었다.

usr/local 아래에 java라는 폴더를 생성해 압축해제 한 jdk 폴더를 옮긴다.
*이동명령: sudo mv 소스위치 타겟위치
-환경변수 설정
JAVA_HOME=/usr/local/java/jdk-14.0.1/
JRE_HOME=$JAVA_HOME/jre
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin

cd etc로 위치를 이동해 profile 편집창을 연다.
*sudo gedit profile

위의 부분은 고대로 두고 맨 아래에 환경변수를 설정한다.

거듭 오탈자 확인을 한 뒤 export 명령을 작성하고 저장한다.

profile 창을 닫은 뒤 cat 명령으로 profile을 읽어온다.

잘 설정되었다.

reboot 명령으로 재부팅한 뒤 다시 명령창을 열어 java 버전을 확인한다.
4. Hadoop 설치
하둡 다운로드 후 압축 풀어 /usr/local/hadoop 식으로 설치 할거다.

Apache 홈페이지에 들어간다.

Hadoop을 찾는다.

다운로드

미러 사이트로 간다.

제일 첫 번째 사이트를 선택한다.

2.7.7 버전을 선택한다.

src는 설치가 조금 더 복잡하기 때문에 아래 파일을 다운받는다.

다운로드즁...

완료쓰
-설정

아직 Hadoop이 다운로드 중이기 때문에 명령창을 추가로 열어

그룹을 생성한다.
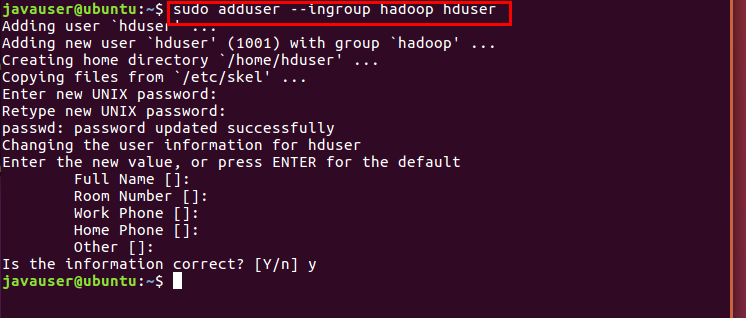
생성한 그룹에 hduser라는 계정을 생성한다.

계정 정보 검색 뒤, home으로 이동해 list를 확인한다.
이번에는 etc로 간다.

sudoers의 내용을 확인한다.
*cat: 내용을 보는 명령
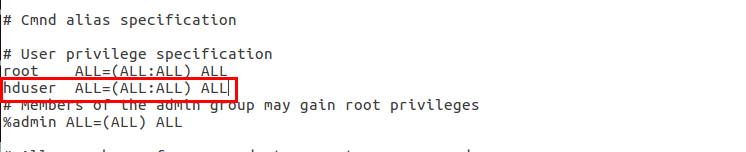
gedit 명령을 사용해 root 밑에 hduser를 추가한다.
-openssh-server 설치
: 이후 분산서버 설정 시 필요(우리는 가상 분산모드로 설치할 예정이기 때문에 사실 꼭 필요한 것은 아니다.)
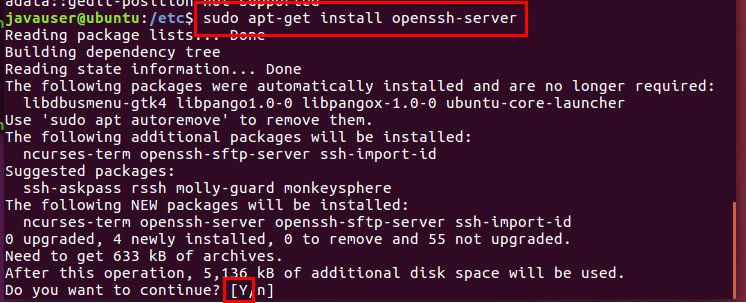
설치

설치된 ssh를 사용할 수 있도록 hduser에게 Admin 권한을 줬다.

보안키 생성
아래의 그림이 보안키다...

*>>: 다이렉션, 기존의 내용 다음에 추가한다.
시스템 컨트롤 환경설정 편집창을 연다.
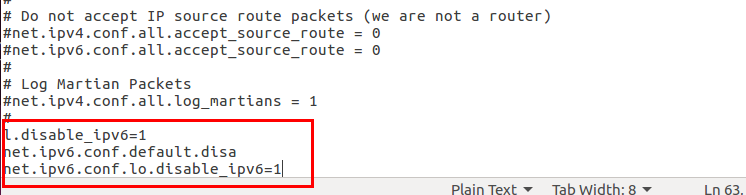
맨 아래에 내용을 추가한다.
cat /etc/sysctl.conf
-환경변수 설정

hduser에게 권한 부여

다운로드 폴더의 리스트 명령
소유자 javauser, 소유 그룹 javauser

*tar: 파일을 묶거나 풀 때 사용
*tar zxvf 폴더 혹은 파일: 해당 폴더나 파일을 묶어서 tar.gz 확장자로 만든다.
*tar zxvf xxx.tar.gz: 해당 파일을 압축해제한 뒤 폴더화한다.
권한 어쩌구 오류가 나서 exit 뒤 javauser로 압축해제했다.
(tar zxvf hadoop~)

압축해제한 파일을 hadoop 폴더로 옮긴다.

소유권을 hduser로 변경한다.
*chown(changing owner): 파일이나 폴더에 대한 소유권 변경

local 아래에 hadoop_tmp, hdfs, namenode 폴더를 생성한다.
-p: 여러 개의 폴더를 동시에 만들 때, parent, parent의 약자, 부모 폴더 생성

리눅스에서는 트리 명령을 사용하려면 트리를 설치해야 한다.

생성한 hadoop 폴더의 구조를 파악하기 위해 tree 명령을 사용한다.

namenode와 같은 위치에 datanode 폴더를 만든 뒤,

역시 소유권을 hduser로 변경한다.

hduser의 홈 디렉토리
*ls: 폴더 하부 목록 출력
*ls -l: 보다 상세하게 목록 출력(소유권, 소유자, 권한, 날짜, 크기 등)
*ls -al: ls -l + 숨겨진 목록까지 출력(all)

gedit .bashrc 하단에 내용 추가
: 해당 명령을 곧바로 실행하기 위해 환경변수 추가
export JAVA_HOME=/usr/local/java/jdk-14.0.1
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:/usr/local/hadoop/bin/

다른 건 건드리지 말고 맨 아래에 입력한다.
*bin: 일반적인 명령
*sbin: 하둡을 시작하거나 중지시키는 명령

편집한 bashrc파일을 확인한다.(cat)

잘 입력되었다.
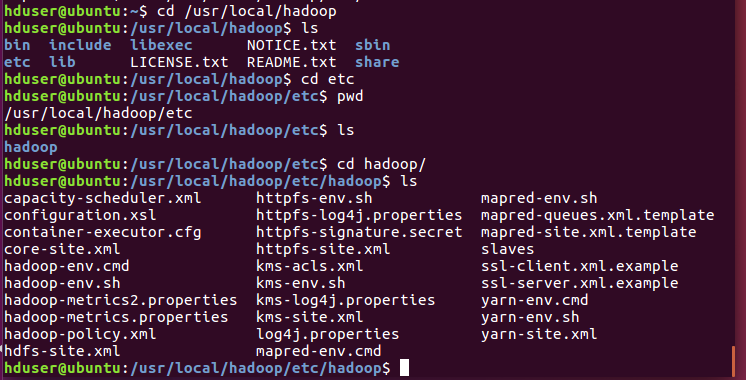
hadoop 폴더에서 리스트 확인

-hadoop-env.sh 파일 편집

네모박스 친 부분만 바꿔준다.

-core-site.xml 파일 편집

configuration에 property 추가

잘 썼는 지 확인

-hdfs-site.xml 편집
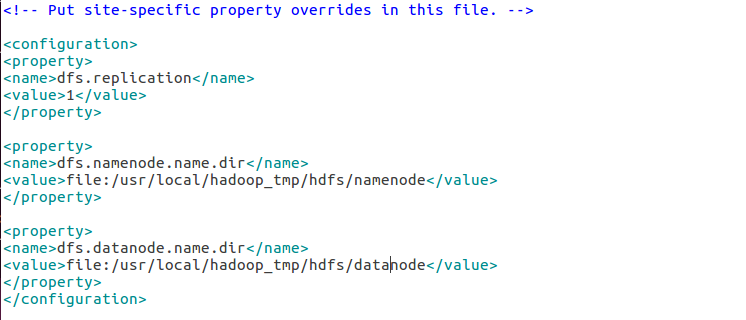
property 추가추가추가

-mapred-site.xml 편집

하려고 했는데 파일이 비어있다.

mapred 리스트를 확인

mapred-site 템플릿 파일을 mapred-site.xml에 복사해 넣는다.

내용이 생겼다.
<configuration>
<property>
<name>mapred.jab.tracker</name>
<value>localhost:54311</value>
</property>
</configuration>
property 추가

-마지막으로 yarn-site.xml 편집

property 추가추가
-하둡에 대한 설정
---core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:54310</value>
</property>
</configuration>
---hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
-> 1인 경우, 가상 분산모드 / 3인 경우 완전 분산모드(리눅스 두 개 더 깔아야 한다...)
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop_tmp/hdfs/namenode</value>
</property>
->namenode: 데이터 정보를 담고 있는 서버의 위치
namenode가 datanode를 관리
->datanode: 실제 데이터가 저장되는 서버
<property>
<name>dfs.datanode.name.dir</name>
<value>file:/usr/local/hadoop_tmp/hdfs/datanode</value>
</property>
</configuration>
---mapred-site.xml
실제 빅데이터를 분석, 처리하고 작업하는 서버(map + reduce)
job: 일꾼 관리자, mapred 하부에서 일하는 애들
task: 일꾼, job이 태스크를 만들어 일한다.
<configuration>
<property>
<name>mapred.jab.tracker</name>
<value>localhost:54311</value>
</property>
</configuration>
---yarn-site.xml
yarn: hadoop서버를 컨트롤하는 관리자(하둡을 대리하는 에이전트 같은 느낌)
하둡의 제어권을 얀으로 넘겨준다.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
<configuration>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
5. Hadoop 실행 확인

hadoop 아래의 sbin으로 가 start 명령

yarn start
jps 명령 뒤 뭐가 여섯 개 뜨면 성공적으로 설치된 것이다..!








./hadoop namenode -fromat
./start-yarn.sh
jps
'20.03 ~ 20.08 국비교육 > Data (Hadoop, R)' 카테고리의 다른 글
| [Hadoop] 다수의 파일 출력(Multiple Outputs) (0) | 2020.06.29 |
|---|---|
| [Hadoop] 데이터 입력 (0) | 2020.06.25 |
| [Hadoop] Wordcount (0) | 2020.06.25 |
| [Hadoop] Eclipse에서 Hadoop 실행하기 (0) | 2020.06.25 |
| [Hadoop] Window에 Hadoop 설치하기 (0) | 2020.06.24 |