<윈도우에 설치>

zip파일을 압축해제한다.

D에 하려고 했지만 편의상 C로 옮겼다.

환경 변수를 설정할 것이다.

새로 만들기

하둡 홈이라는 변수를 만들고, 하둡 디렉토리의 경로를 지정한다.

경로 설정

새로 만들기
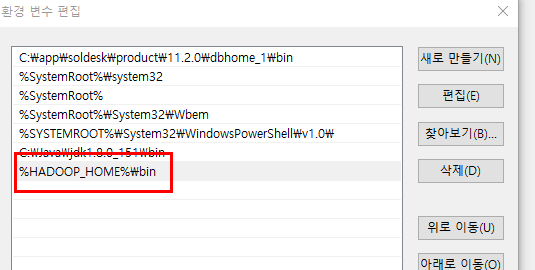
하둡의 bin을 지정한다.

C 드라이브에서 목록 확인 뒤

하둡 디렉토리의 bin으로 이동해 목록을 확인한다.

명령어

C 드라이브에 가면 tmp폴더가 생성되었다.

대충 이런 느낌

sbin에서 하둡을 실행시킨다.
-비권장모드
start-dfs
start-yarn
-권장모드
stop-dfs
stop-yarn

창 4개가 열리면 성공적으로 실행되는 것이다.
<구동>

하둡 - 빈에 간단한 텍스트 파일을 저장하고,

하둡 - mapreduce에서 examples.jar 파일을 갖고와

빈에 붙여넣는다.
hdfs dfs -mkdir /big
hdfs dfs -put bigdata.txt /big
hdfs dfs -ls /big
yarn jar hadoop-examples 어쩌구 .jar wordcount big/bigdata.txt /out
hdfs -cat /out/part-r-00000
'20.03 ~ 20.08 국비교육 > Data (Hadoop, R)' 카테고리의 다른 글
| [Hadoop] 다수의 파일 출력(Multiple Outputs) (0) | 2020.06.29 |
|---|---|
| [Hadoop] 데이터 입력 (0) | 2020.06.25 |
| [Hadoop] Wordcount (0) | 2020.06.25 |
| [Hadoop] Eclipse에서 Hadoop 실행하기 (0) | 2020.06.25 |
| [Hadoop] Linux에 Hadoop 설치하기 (0) | 2020.06.23 |